ảnh minh họa
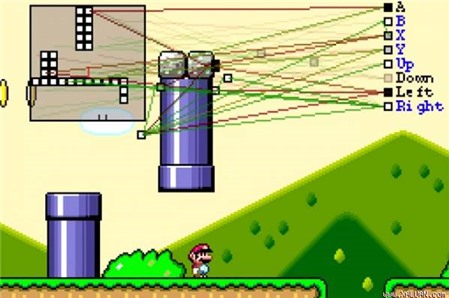
Sau mỗi lần thua, chương trình sẽ rút kinh nghiệm và ghi nhớ phân đoạn đó ở trên đường đi để đưa ra hướng giải quyết khác và bắt đầu "học tập" dần dần từ đó. Chỉ cần qua 34 lần thử nghiệm, hay có thể nói ví von là "tiến hóa", trí thông minh nhân tạo này có thể kết thúc màn chơi một cách hoàn hảo.
Mặc dù đây chỉ là một demo khá thành công nhưng vẫn còn một chặng đường rất dài để một cỗ máy có thể học và giải được những thuật toán phức tạp hơn.
MarI/O - Machine Learning for Video Games
XEM VIDEO CLIP: qv6UVOQ0F44